

If you are a beginner to Apache Spark, this post on the fundamentals is for you. Mastering the basics of Apache Spark will help you build a strong foundation before you get to the more complex concepts.
Often times these concepts are mixed with new terminology. Associating these terminologies using relationships in a hierarchical way helps understand information effectively, and in a shorter time frame. That’s the concept behind mind maps, which is used in this post.
A mind map is a technique use to organize information visually, increasing the brain’s ability to retain information dramatically. For more information on mind mapping, read this.
What is Apache Spark?
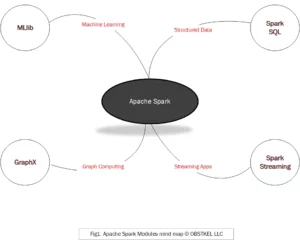
Apache Spark is a data processing engine. You can use Spark to process large volumes of structured and unstructured data for Analytics, Data Science, Data Engineering and Machine Learning initiatives.
However, it’s important to note that Apache Spark is not a database or a distributed file system. In other words, it is not meant to store your data. Rather, Spark provides the raw processing power to crunch data and extract meaningful information. Spark provides 4 modules for this –
- GraphX: Used to process complex relationships between data using Graph theory concepts of Nodes, Edges and Properties.
- MLlib: An extensive Machine Learning library and tools to build smarter apps and prediction systems.
- Spark Streaming: For processing real-time data for analytics.
- Spark SQL: Build interactive queries for batch processing on structured data.
Apache Spark is not limited to a single programming language. You have the flexibility to use Java, Python, Scala, R or SQL to build your programs. Some minor limitations do apply.
If you are just starting off and do not have any programming experience, I highly recommend starting off with SQL and Scala. They are the 2 most popular and in demand programming languages for Apache Spark!
What is Apache Spark RDD?
RDD in Apache Spark stands for Resilient Distributed Dataset. It is nothing more than your data file converted into an internal Spark format. Once converted, this data is then partitioned and spread across multiple computers(nodes).
The internal format stores the data as a collection of lines. This collection can be a List, Tuple, Map or Dictionary depending on the programming language you chose (Scala, Java, Python).
Resilient Distributed Dataset (RDD) does sound intimidating. So, keep things simple. Just think of it as data in Apache Spark internal format.
Moving beyond theoretical, there are two main concepts you need to grasp for RDD’s.
- First, how do I convert external data into Spark format (Creating an RDD).
- Second, now that I created an RDD, how to do operate on it.
Let’s use the Apache Spark mind map below to visualize this process.
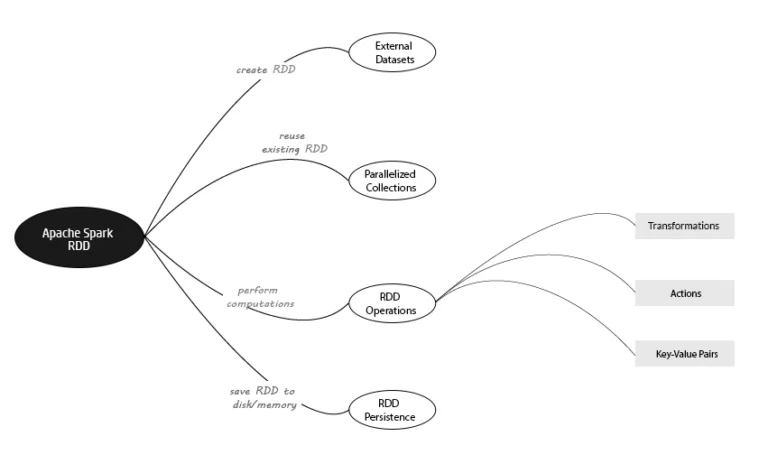
Creating Spark RDD's from External Datasets
External Datasets in Apache Spark denotes the source data stored externally. This data needs to be read in to create an RDD in Apache Spark. There are 2 key aspects when it comes to external data sets: location and file format.
- Location: This is where your data is located. Spark can get to your source data from the below sources.
- Amazon S3
- Cassandra
- HBase
- Hadoop Distributed File System (HDFS)
- Local File System
- File Format: Your file format defines the structure of the data in your file. Apache Spark can read source files in the below formats.
- Avro
- Optimized Row Columnar (ORC)
- Parquet
- Record Columnar File (RCFILE)
- Sequence files
- Text files
Benefit of RDD Persistence in Spark
If an RDD needs to be used more than once, you can choose to save it to disk or memory. This concept is called RDD Persistence.
The benefit of RDD Persistence is that you do not have to recreate distributed datasets from external datasets every time. In addition, persisting datasets in memory or disk saves processing time down the road.
Reusing RDD's using Parallelized Collections
As I mentioned earlier, an RDD is any source data expressed as a collection. Persistence allows you to save this data so you can reuse it.
So, how do you reuse an existing RDD?
You create a Parallelized Collection. A Parallelized Collection creates a new RDD by copying over the elements from an existing collection (RDD). This creates a new distributed dataset.
In many ways, this is similar to creating a table from another table in a database using a CREATE TABLE AS (CTAS) statement.
Performing Operations on RDD's
Now that you know how to create an RDD and reuse an RDD, let’s look at performing operations on datasets.
Operations are what you do with your collection or the elements in your collection to achieve an end result. There are 4 types of RDD Operations you can perform in Apache Spark.
- Actions: An action operation returns a value based on computation performed on your RDD. A perfect example would be performing a count on the number of elements in a collection. For a list of Apache Spark actions, click here.
- Transformations: A transformation operation on the other hand executes a function on an RDD and returns the results as new RDD. Union, Filter and Map are some common examples of transformation functions. For a detailed list of Apache Spark transformations, click here.
- Key-Value Pairs: Key-Value pairs are data structures containing 2 elements. The first element is the name, and the second the value. To handle this variation, there are certain RDD operations in Scala (PairRDDFunctions) and Java (JavaPairRDD), specifically designed for Key-Value Pairs.
Your takeaway from this post
Yes, everything about Apache Spark sounds intimidating! The acronyms, the keywords, the language!
But don’t let that get to you. Approach Spark the same way you would eat an elephant- “One small bite at a time.”
Your takeaway from this post should be –
- An understanding of what Apache Spark is.
- The different features of Apache Spark.
- The importance of RDD and how to create one.
- The different types of Operations you can perform on an RDD (Actions, Transformations).
Spark SQL links
Programming Guide
The official Apache Spark v2.3.2 Spark SQL Programming Guide with everything you need to know in a single place.
Hive Tutorial
Learn how Apache Hive fits into the Hadoop ecosystem with this Hive Tutorial for Beginners on guru99.com.
